![Information Workers [BLOG]](/wp-content/uploads/2023/08/Cabecera-BLOG.png)
El Machine Learning se ha convertido en una herramienta esencial para los negocios de todos los tamaños. Sin embargo, el despliegue y administración modelos de ML puede ser complejo y consumir mucho tiempo. MLOps es un conjunto de prácticas que ayudan a automatizar y optimizar el ciclo de vida de un modelo de ML, desde la preparación de los datos hasta el despliegue y monitoreo.
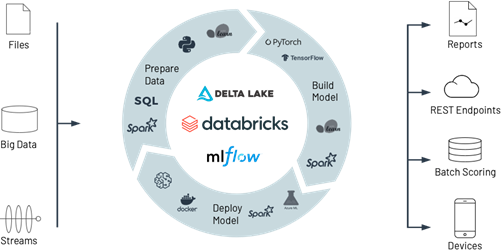
Fuente: LinkedIn. (2021). Databricks with Machine Learning flow all in one solution
En este blog hablaremos de los beneficios de usar Databricks para MLOps y revisaremos el proceso de MLOps. Pero ¿Por qué Databricks es una plataforma popular para aplicar MLOps? Esto es debido a que Databricks aprovisiona un ambiente unificado para la preparación de los datos, entrenamiento de los modelos y despliegue de los mismos. También ofrece algunas características que ayudan a automatizar y escalar flujos de trabajo de MLOps de forma rápida y sencilla.
Ahora, ¿Por qué necesitamos MLOps?
Como lo dijimos al inicio, pasar a producción modelos de Machine Learning es una tarea difícil. El ciclo de vida de estos proyectos consiste en muchos componentes complejos tales como: la ingesta de datos, la preparación de estos, el entrenamiento de modelos y tener la total claridad en estos procesos. También requiere colaboración de diferentes equipos, por ejemplo, el ingeniero de datos para disponibilizar la data, el científico de datos para entrenar el modelo y un desarrollador o ingeniero de Machine Learning para desplegar el modelo a producción, es decir donde el modelo va a cumplir con su principal objetivo. Todo esto requiere una muy buena coordinación de los equipos involucrados para mantenerlos a todos trabajando de forma sincrónica. MLOps abarca la experimentación, iteración y el mejoramiento continuo de un modelo de ML.
De igual forma, usar Databricks para MLOps nos trae beneficios como:
Si quieres seguir leyendo este articulo ingresa al siguiente link https://www.iwco.co/como-administrar-modelos-de-machine-learning-en-databricks/