![Information Workers [BLOG]](/wp-content/uploads/2023/08/Cabecera-BLOG.png)
Antes de iniciar, es necesario que tengas los siguientes insumos listos!
- Cadena de conexión a tu SQL Server
- Archivo JAR con el Driver (Aquí se pueden descargar)
Lo primero que vamos a hacer es crear un bucket en Google Cloud en donde almacenaremos los archivos jar que vamos a utilizar
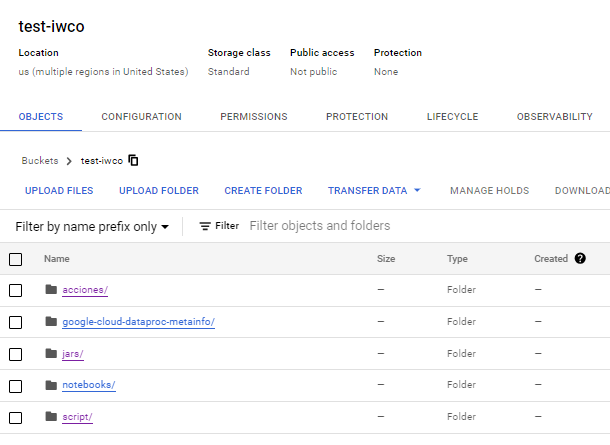
En este bucket que yo he llamado test-iwco vamos a crear 2 carpetas que utilizaremos mas adelante.
- acciones
- jars
En la carpeta jars debemos subir los archivos que hemos descargado previamente
En la carpeta acciones, subiremos un archivo shell que contiene lo siguiente:
#!/bin/bash
JAR_PATH=/usr/local/lib/jars
mkdir $JAR_PATH
# JDBCs
JDBC_ORA=ojdbc8-21.7.0.0.jar
JDBC_SQL=mssql-jdbc-6.4.0.jre8.jar
JDBC_PGSQL=postgresql-42.2.6.jar
gsutil cp gs://test-iwco/jars/$JDBC_ORA $JAR_PATH/
gsutil cp gs://test-iwco/jars/$JDBC_SQL $JAR_PATH/
gsutil cp gs://test-iwco/jars/$JDBC_PGSQL $JAR_PATH/Este archivo lo almacenaremos con el nombre init_actions.sh y lo cargaremos en la carpeta acciones del bucket creado previamente.
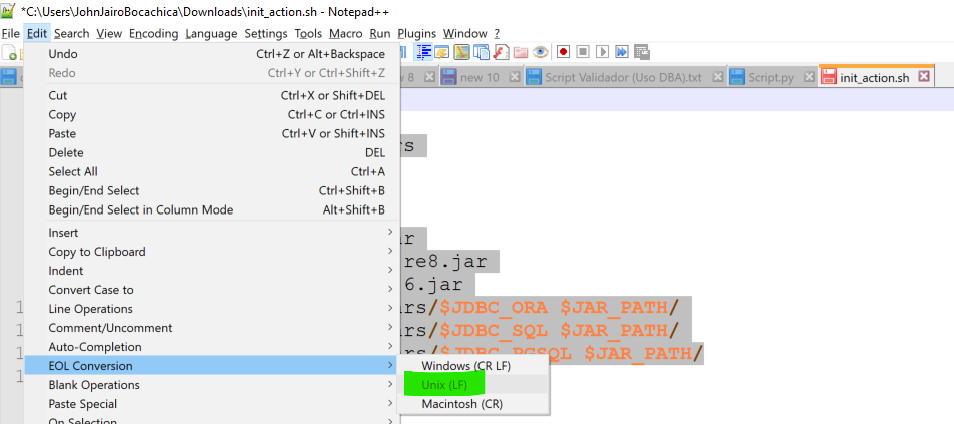
NOTA: Es posible que el archivo init_actions.sh les presente problemas, para esto, en notepad++ cambien el sistema de cambio de lineas de windows a UNIX
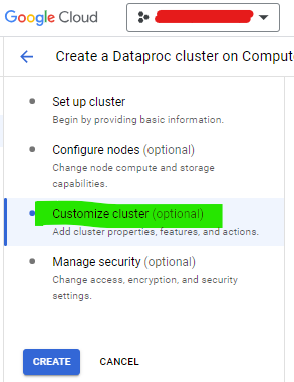
Ahora es momento de crear el cluster!!
- Inicia el proceso de creacion del cluster de Dataproc, selecciona las configuraciones necesarias para tu proyecto
- Da clic en Personalizar Cluster (Customize Cluster)
- Ahora ve a Propiedades del Cluster (Cluster Properties) y agrega 3 propiedades
| Prefijo (Prefix) | Llave (Key) | Valor (Value) |
| spark | spark.jars | /usr/local/lib/jars/* |
| spark | spark.driver.extraClassPath | /usr/local/lib/jars/* |
| dataproc | dataproc.conscrypt.provider.enable | false |

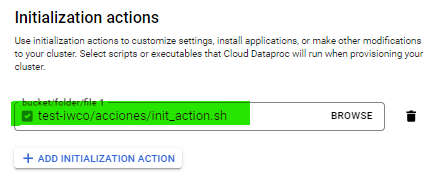
En las acciones de inicialización del cluster (Initialization Actions), seleccionaremos el archivo shell que cargamos previamente
Ya podemos lanzar la creación de nuestro cluster y comenzar a utilizarlo, un script de ejemplo en pyspark para comprobar la conectividad:
options = {
"url":"jdbc:sqlserver://<SERVIDOR>:<PUERTO>;database=<BASE DE DATOS>",
"driver":"com.microsoft.sqlserver.jdbc.SQLServerDriver",
"dbtable":"sys.tables",
"user":"<USUARIO>",
"password":"<PASSWORD>"
}
df = spark.read.format("jdbc").options(**options).load()Buen codigo y buena compilación!