![Information Workers [BLOG]](/wp-content/uploads/2023/08/Cabecera-BLOG.png)

Merge Into y su gran utilidad en Databricks, ¡¡¡ hoy te lo contamos !!!
Merge Into es una sentencia que nos permite realizar operaciones SQL como las famosas UPSERT (Update con Insert), en esencia podemos realizar Update, Insert y Delete cuando se cumplan o no determinadas condiciones lógicas, veremos siempre que una de esas condiciones es que haya o no un cruce (join) de los atributos determinados entre las tablas elegidas. Adicionalmente, podemos agregar condiciones (similar al where SQL) para que se cumplan o no y así poder elegir la operación a realizar.
Normalmente en el Merge Into, cuando existe un cruce actualizamos y cuando no existe el cruce insertamos nuevos datos o los eliminamos, esta es la forma general y básica como trabaja el Merge Into. Este tipo de tecnología puede utilizarse y se enfoca especialmente en aplicaciones de Data Warehouse (Bodegas de Datos).
Vamos directamente a explicar cómo usar Merge Into en Databricks, para ello iremos directo al ejemplo ilustrativo y posteriormente iremos explicando las dudas que vayan surgiendo.
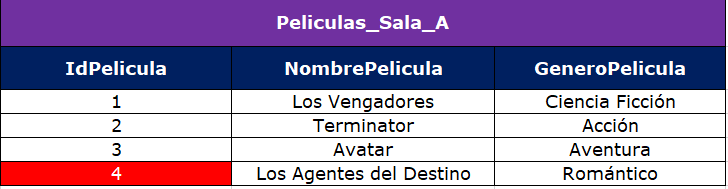
Tenemos dos conjuntos de datos, un primer conjunto denominado Peliculas_Sala_A y un segundo conjunto denominado Peliculas_Sala_B, cada uno dispone de un identificador de película (IdPelicula), el nombre de la película (NombrePelicula) y el género de la película (GeneroPelicula), como se observa a continuación:
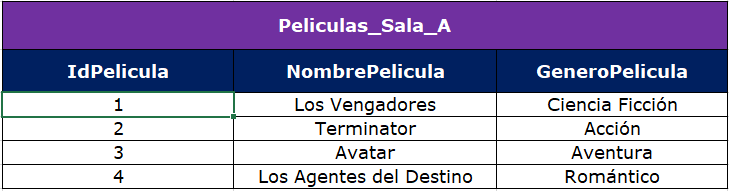
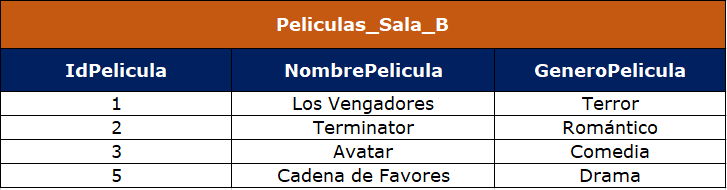
Como nos podemos dar cuenta, el GeneroPelicula de Peliculas_Sala_B no es acorde y hay que actualizarlo, para esto haremos un merge into con update, como sigue:

Aquí lo que estamos haciendo es: con merge into le decimos que nos modifique esa tabla Peliculas_Sala_B, el B que aparece seguido de la tabla es el alias asignado para trabajar con mayor facilidad y comodidad, después le decimos que vamos a usar Peliculas_Sala_A con using y que todo ese cruce lo haga por medio del atributo o columna IdPelicula. Finalmente todo se reduce a actualizar las filas que sí cruzaron (when matched then update), que son las del identificador 1,2 y 3, como se puede observar a continuación:
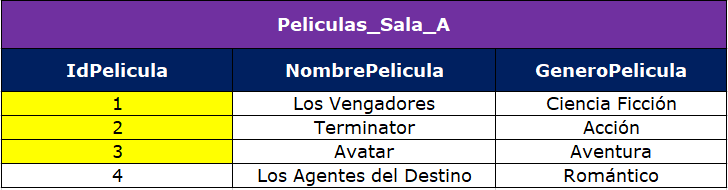
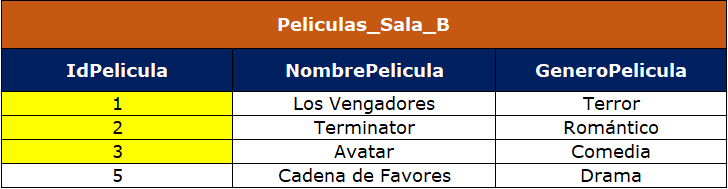
Después de identificar los cruces, se procede a actualizar la tabla Películas_Sala_B de la siguiente forma:
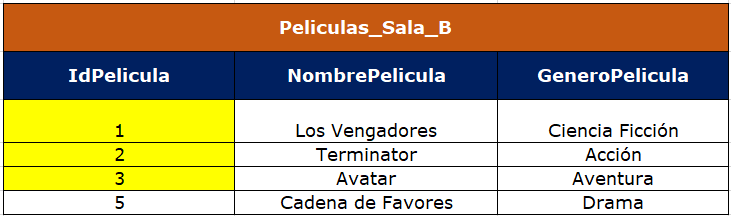
Vemos que en la tabla Peliculas_Sala_B ya están los géneros correspondientes a cada película.
Ahora vamos a ver el merge into con insert, basado en el anterior conjunto de datos que produjo el update.

Aquí lo que estamos haciendo es: con merge into le decimos que nos modifique esa tabla Peliculas_Sala_B, el B que aparece seguido de la tabla es el alias asignado para trabajar con mayor facilidad y comodidad, después le decimos que vamos a usar Peliculas_Sala_A con using y que todo ese cruce lo haga por medio del atributo o columna IdPelicula. Finalmente todo se reduce a insertar las filas que no cruzaron (when not matched then insert), que son las del identificador 4 y 5 como se puede observar a continuación:
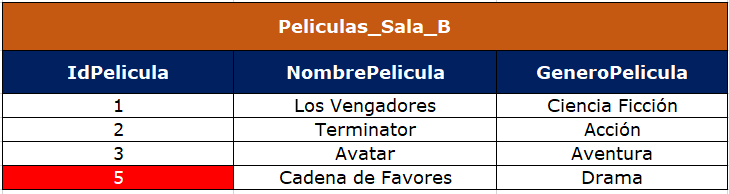
Miramos que las filas que no han cruzado son el identificador 4 y 5, por lo tanto siguiendo la orden que le enviamos a Databricks, vamos a insertar en B.IdPelicula lo que tenga A.IdPelicula, así mismo en B.NombrePelicula lo valores contenidos en A.NombrePelicula y finalmente en B.GeneroPelicula lo que contenga A.GeneroPelicula, de esta forma Peliculas_Sala_B queda así con los datos ya actualizados y la nueva fila insertada exitosamente:
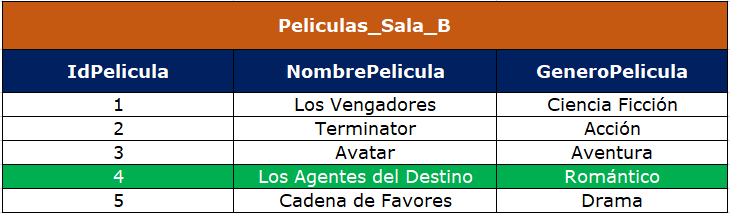
Por último es importante mencionar que las anteriores ordenes en Databricks pueden ser ejecutadas en un sólo paso sin necesidad de dividirlas en varios pasos, esto también ahorra tiempo, espacio y facilita el entendimiento del código, se lo realiza de la siguiente forma:

Merge into es muy usado en la actualidad porque:
- Permite con una misma sentencia realizar operaciones múltiples con diversas condiciones lógicas.
- La sentencia puede paralelizarse de forma transparente.
- La lectura de esta sentencia es fácil y cómoda, de este modo es muy entendible
- El rendimiento de la base de datos mejora ya que, al necesitarse menos sentencias SQL para realizar las mismas operaciones, también se necesitan menos accesos a las tablas con las que se va a cruzar.