![Information Workers [BLOG]](/wp-content/uploads/2023/08/Cabecera-BLOG.png)
¿Alguna vez has necesitado realizar una conexión desde un notebook de Python (AI Platform) a un blob dentro de Cloud Storage, con el objetivo de procesar los datos allí almacenados y analizarlos de acuerdo con las necesidades de negocio? ¡Hoy te contamos cómo puedes lograrlo fácilmente!
Los servicios de almacenamiento como Cloud Storage otorgan la ventaja de guardar data cruda y procesada, como fuente y destino en un proyecto en desarrollo. Entonces, en este blog se explica cómo utilizar tanto Cloud Storage como AI Platform que son herramientas que nos ofrece Google dentro de su plataforma en la Nube (GCP).
Antes de comenzar:
- Asegúrese de tener una cuenta en GCP con facturación activa.
- Cree un Bucket en Cloud Storage donde cargue el archivo a conectarse.
- Cree un notebook en la sesión de AI Platform para generar el código de conexión.
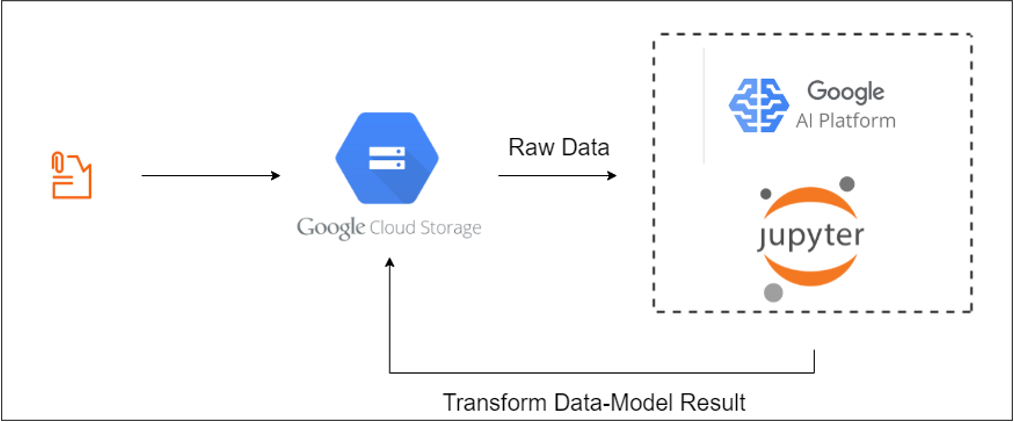
En la Ilustración 1, se esquematiza la arquitectura necesaria para realizar la conexión.
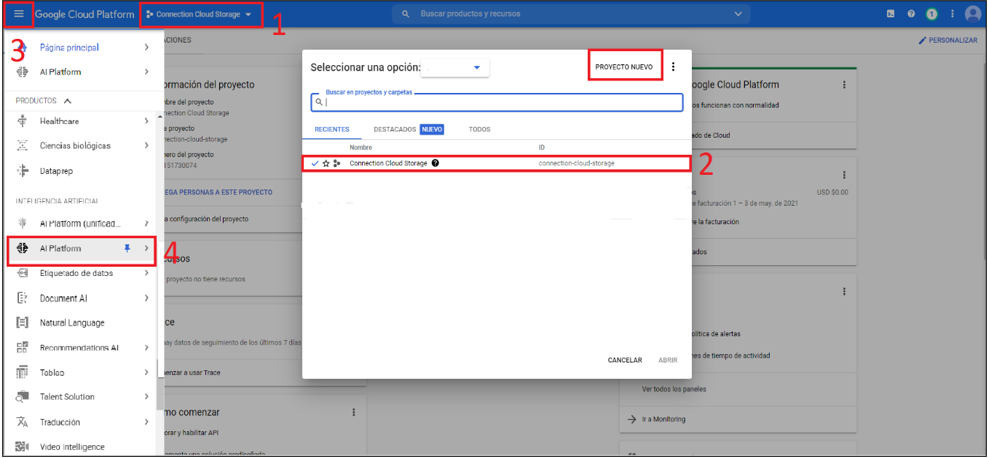
Primero acceda a la consola de Google Cloud:
- Diríjase a la sección de proyectos.
- Cree o seleccione un proyecto (recuerde que este proyecto debe tener habilitada la facturación).
- Posteriormente diríjase al panel izquierdo.
- Seleccione AI Platform.
Los pasos descritos anteriormente, se muestran y etiquetan en la Ilustración 2.
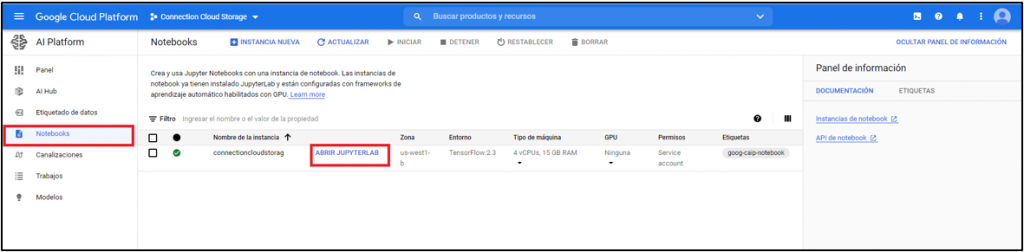
Después de seleccionar, la opción de “AI Platform”, encontrará las opciones que se visualizan en la Ilustración 3, entre ellas los notebooks creados, haga clic sobre la alternativa de “Notebooks” y en el panel derecho se muestran el nombre de estas instancias, para acceder a la de su interés haga clic sobre la opción “ABRIR JUPYTERLAB”.
Cuando tenga abierto el notebook deberá tener en cuenta o llevar a cabo ciertos pasos para hacer una correcta conexión al blob.
1.Instalar dentro del entorno de desarrollo de Jupyter la biblioteca de Google para Cloud Storage, la línea de código se muestra en la Ilustración 4.

2. Importar de la biblioteca algunos métodos necesarios para la conexión, dichos métodos se visualizan en la Ilustración 5.

3. Es indispensable utilizar la función Client ( ) del método storage, porque esta le ofrecerá ciertos atributos que le permitirán acceder de manera rápida tanto a los Buckets que tenga creados en el Storage como a los blobs almacenados en cada Bucket. Una manera sencilla de trabajarlo es asignando la función a una variable para posteriormente hacer uso de sus atributos, como se aprecia en la Ilustración 6.

4. Paso Opcional: Una vez haya realizado los pasos anteriores puede comprobar la conexión global a Cloud Storage, para esto se recomienda obtener desde Python la lista de todos los buckets que tenga en el servicio, a esta lista se llega utilizando el atributo list_buckets de la función Client, el código para realizar lo mencionado en este párrafo se observa en la Ilustración 7.

5. Para dirigirse a la ruta donde se encuentra su archivo, debe realizar la conexión al Bucket específico donde este alojado, este paso se logra usando el atributo get_bucket, y en la Ilustración 8 se aprecia la manera correcta de realizarlo.

6. Para acceder a los datos completos que contiene el archivo es necesario que especifique la URL completa referente a la ubicación de este dentro de Cloud Storage, para esto haga uso del atributo from_string del segundo método que se importó y como se visualiza en la Ilustración 9.

Cabe anotar que dentro del Bucket se pueden crear carpetas para cargar archivos y darle una mejor organización al almacenamiento, si es su caso en el parámetro de entrada del atributo debe especificar también el nombre la carpeta como parte de la ruta de acceso. En caso de no conocer la ruta de la ubicación del archivo, es viable obtenerla con el atributo que se muestra en la Ilustración 10.

7. En este paso ya se ha establecido la conexión al Cloud Storage y se ha accedido a un archivo específico, pero para procesar los datos desde el Notebook de Jupyter se debe hacer una descarga del blob desde Cloud Storage al entorno de desarrollo para trabajarlo sin ningún inconveniente, es decir que se debe hacer una copia del blob para hacer las respectivas transformaciones y una vez obtenido el archivo con los datos resultantes este se carga a nuestro Cloud Storage.
En la Ilustración 11, se muestra cómo realizar la descarga de nuestro blob a la ruta de ubicación del Notebook.

8. Al momento de haber procesado y obtenido los datos, estos se cargan a un Bucket y blob de su preferencia para almacenarlos, se debe realizar la operación que se aprecia en la Ilustración 12.

Recuerde que bucket_trabajo es la variable que se creó para hacer la conexión con un Bucket específico, esto se mostró en el paso cinco. Como parte complementaria, se muestra como copiar un blob de un Bucket a otro y como eliminarlo directamente desde un Notebook, lo mencionado en el presente párrafo se aprecia en la Ilustración 13.

Finalmente, se ha obtenido una conexión exitosa a Cloud Storage y a los datos del archivo de interés, para su posterior procesamiento, si desea validarlo puede ingresar al servicio de Cloud Storage y navegar entre su Bucket y blobs para corroborar que fueron cargados, copiados y eliminados efectivamente según la acción que se haya realizado.