![Information Workers [BLOG]](/wp-content/uploads/2023/08/Cabecera-BLOG.png)
Con el acelerado crecimiento de los datos en nuestros negocios llega un punto en dónde es imprescindible peguntarnos como es la mejor manera de relacionarnos con nuestros datos a la hora de realizar analítica sobre ellos. Es entonces cuando entramos a nuestros equipos y empezamos nuestra búsqueda; en pocos minutos nos habremos encontrado con diferentes lenguajes de programación para realizar las tareas que necesitamos, e incluso nos encontraremos con uno que otro framework de desarrollo a utilizar. Algunos de los más relevantes que aparecerán en nuestro camino serán Python, Pandas y Apache Spark ¿Pero que es Python y cuál es su relación con Pandas y Spark?
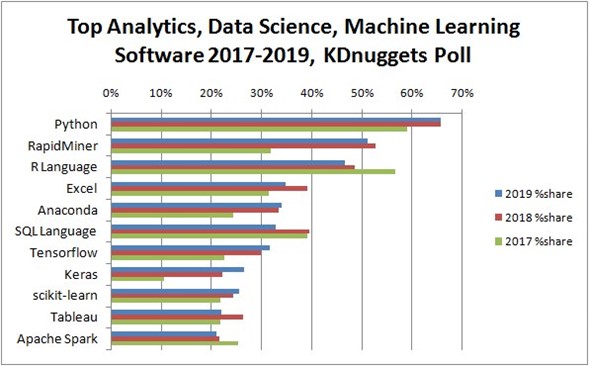
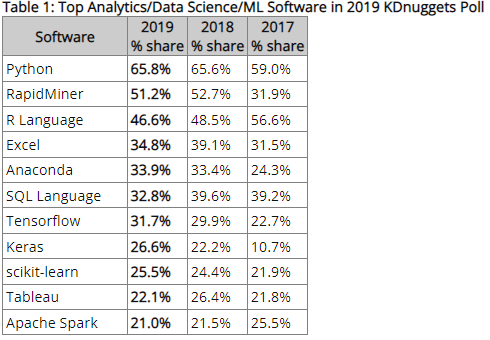
Según Wikipedia, probablemente la primera página que abrirás para conocer más sobre este lenguaje, Python es “un lenguaje de programación interpretado cuya filosofía hace hincapié en la legibilidad de su código. Se trata de un lenguaje de programación multiparadigma, ya que soporta parcialmente la orientación a objetos, programación imperativa y, en menor medida, programación funcional. Es un lenguaje interpretado, dinámico y multiplataforma.”. Pero ¿Porqué es el lenguaje más utilizado y apetecido en el análisis de datos?
La respuesta es simple, facilidad de uso, gran comunidad y, librerías. Con la disponibilidad de librerías y paquetes como NumPy, Pandas, Scikit-Learn, Keras, Seaborn, entre otros, Python ha logrado convertirse en la herramienta preferida en el mercado de la analítica de datos y del machine learning. Ahora bien, el principal paquete que encontraras para iniciar el análisis sobe tus datos será Pandas, un paquete de librerías de código abierto de gran eficiencia que te permite explorar, analizar, limpiar y modificar tus datos.
¿Es entonces Pandas la herramienta que debes utilizar? La respuesta sería depende, ya sea de tus datos y/o del problema que quieras abordar. En el mundo de la analítica de datos, frecuentemente te encontraras en la situación en donde deberás pensar los problemas que quieres abordar, desde la madurez y estado de tus datos, ¿Con qué datos cuento? ¿Son suficientes los datos que tengo? ¿Necesito algún modelo de analítica?¿Qué tipo de modelo se acopla mejor a lo que necesito?. En el momento que te encuentres con esas preguntas, será el momento de pensar como empezarás tu acercamiento a tus datos, y será el momento de analizar tu herramientas disponibles.
Pandas es la herramienta ideal cuando el tamaño de tus datos no es muy grande, miles a millones de registros, lo que no es poco en muchas empresas. Con él podrás leer, visualizar y agregar tus datos provenientes de diferentes fuentes de datos CSV, JSON, archivos de texto plano, bases de datos relacionales, e incluso algunas nubes. Siempre y cuando tus datos puedan ser procesados en la memoria RAM de tu máquina y no requieras un procesamiento multi núcleo, Pandas es la opción ideal. Cuenta además con una gran compatibilidad con otros frameworks de desarrollo y paquetes tales como NumPy, TensorFlow, o Sci-kit Learn, que te permitirán llevar tus modelos a otro nivel y realizar analítica muy avanzada.
Apache Spark
Cuando tus datos, sobrepasan la capacidad tu máquina o necesitas realizar un procesamiento paralelo de tus datos, es cuando se empiezan a ver las falencias de Pandas, y en dónde herramientas como Apache Spark empiezan a relucir. Spark es, según wikipedia “un framework de desarrollo en clúster de propósito general orientado a la velocidad, cuenta con APIs en Java, Scala, Python y R”. Cuenta además con diversas herramientas para interactuar con lenguaje SQL, graficar los datos, entre otras cosas. Esto llevado a otras palabras, quiere decir que Spark permite distribuir tus datos en sistemas clusterizados, diversas máquinas trabajando al unísono bajo la orquestación de una máquina maestra, compartiendo recursos de memoria y almacenamiento en todo momento.
Es este comportamiento clusterizado es lo que le permite a Spark relucir en algunos aplicativos donde Pandas flaquea. Si bien ambos frameworks de desarrollo tiene una finalidad muy similar, la fuente de los datos, las librerías y la forma en la que ejecutan las acciones es lo que los diferencia. Esto último, hace referencia a la ejecución “ansiosa” de Pandas vs la ejecución “perezosa” de Spark, donde Pandas ejecuta cada transformación y acción que se le dicte al instante, mientras que Spark espera a recolectar cada una de las transformaciones que se necesiten y solo las ejecuta en el momento que se le solicite realizar una acción (count, display,min, max, etc.); permitiéndole recolectar toda la información necesaria para optimizar la ejecución y desplegar las instrucciones en las diferentes máquinas del clúster.
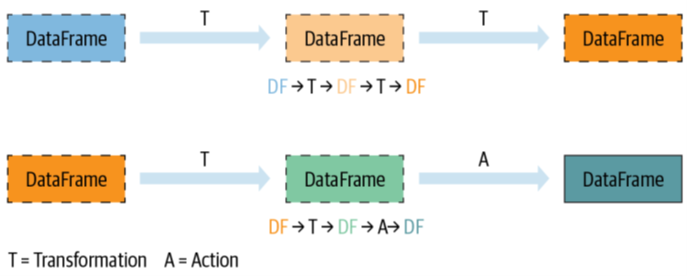
Esto no quiere decir que Spark sea entonces mejor y más rápido en todas las labores que Pandas, todo dependerá de que caso de uso tengas y el tamaño de tus datos. A veces incluso dependerá de las librerías o frameworks con los que quieras conectarte para tus objetivos de analítica de datos. En la siguiente imagen, puedes observar la velocidad de procesamiento para realizar diferentes agregaciones, en una máquina de un solo nodo, a medida que tus datos crecen:
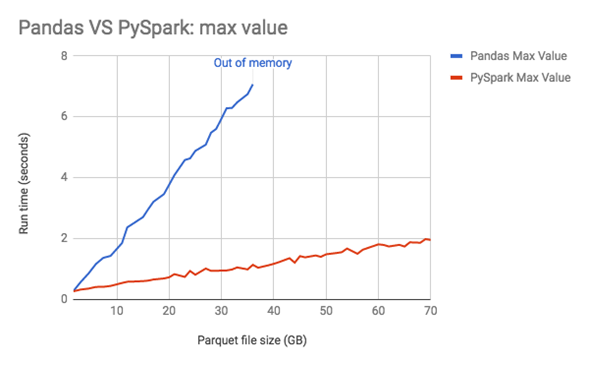
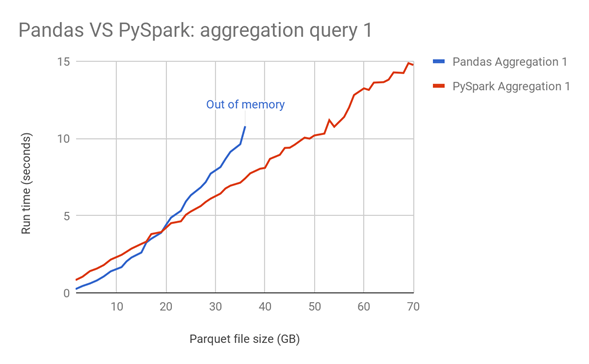
Como puedes ver, Pandas y Spark son realmente ágiles en el procesamiento de información, ejecutando operaciones complejas en cuestión de segundos. Pandas tiene una gran versatilidad y facilidad de manejo que le permite funcionar realmente muy bien en datos que no sean muy grandes. Su conectibilidad con otros frameworks de desarrollo y sus diversas opciones le permiten manipular muy facilmente tus datos y utilizarlos para realizar modelos de analítica sobre los mismo dataframes al instante.
No obstante, gracias a su comportamiento “perezo” que almacena las ejecuciones hasta el momento que se le solicite una acción, Spark puede optimizar el orden de sus acciones manteniendo el linaje entre ellas, para posteriormente ejecutar todo en un sistema multi núcleo y distribuido bajo una misma orquestación, tiendo así un comportamiento más estable a medida que el tamaño de los datos crece. Si bien Spark no cuenta con la misma conectividad con otros frameworks como Pandas, cada día se siguen implementando nuevos métodos, librerías y APIs que permitan ampliar el uso de Spark en el mundo de la analítica de datos.
Ahora que sabes esto, estas un poco más cerca de empezar tu camino en el mundo de la analítica de tus datos – ¿Sabes cual es la herramienta que mas se acopla a tus necesidades en analítica de datos? En Information Workers siempre estaremos dispuestos a ayudarte y guiarte en el proceso!