![Information Workers [BLOG]](/wp-content/uploads/2023/08/Cabecera-BLOG.png)
Databricks se ha convertido en la herramienta preferida para el procesamiento de datos en nube ya que este permite el desarrollo de algoritmos en lenguajes como Scala, Python, Java y SQL. Así mismo permite una manipulación sencilla de archivos tipo csv, parquet y delta, donde el uso de estos se ha venido incrementando debido a que presenta características muy atractivas para los desarrolladores y científicos de datos como lo son el versionamiento y creación de tablas en clúster (también se puede hacer con archivos parquet o csv pero no se pueden modificar). La creación de delta tables permite al desarrollador una forma muy sencilla de modificar los datos del archivo delta ya que permite ejecutar instrucciones SQL para su manipulación, imitando la forma en que se altera una tabla en un servidor SQL.
En este blog vamos a ver los requerimientos y la forma de cómo asignar permisos de acceso a los usuarios o grupos de usuarios de un Workspace Databricks sobre los objetos creados dentro de un clúster de Databricks. Estos Objetos pueden ser tablas o bases de datos . Estos permisos de acceso se asignan para controlar que usuarios pueden modificar o consultar un objeto y de esta manera proteger estos objetos de modificaciones no deseadas. Por otra parte, los grupos de usuarios van a permitir dar un orden mas globalizado sobre cierto grupo de usuarios y no tener que asignar un permiso a cada usuario.
¡Nota!: este tutorial está basado en Azure, para las demás nubes puede variar un poco.
Requerimientos:
- Tener una suscripción de Azure donde vamos a crear nuestro espacio de trabajo.
- Databricks workspace creado en plan premium.
- Clúster de alta concurrencia (Este tipo de clúster permite el control de acceso sobre las tablas).
- Tener habilitado el control de acceso para el Workspace.
- Tener habilitado el clúster para control de acceso a la tabla.
Estos requerimientos serán evidenciados en cada uno de los pasos de desarrollo.
Pasos:
- Crear un Databricks Workspace sobre un plan premium:
Para realizar este paso simplemente vamos al portal de Azure y en el buscador escribimos Azure Databricks, seguidamente damos click en crear y nos aparecerá un entorno de trabajo similar a este.
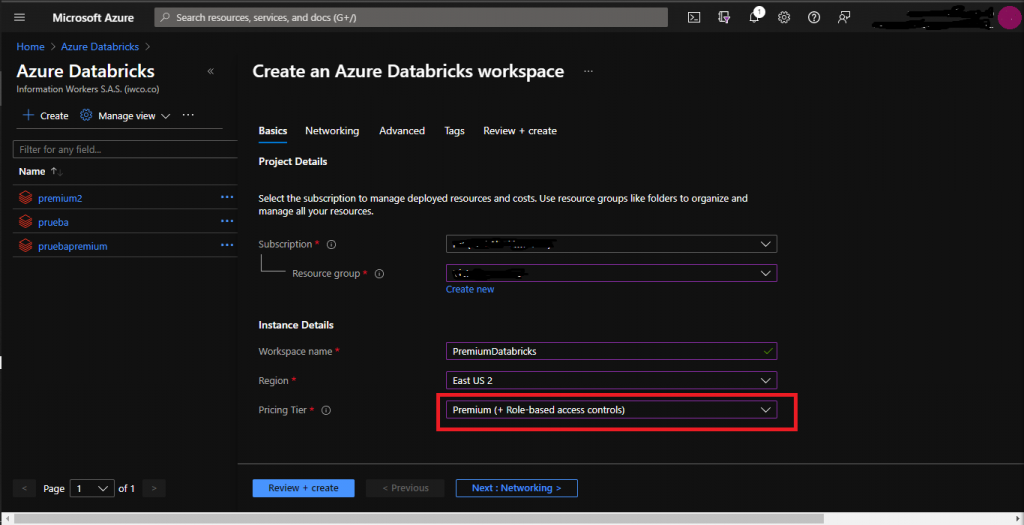
Valores de los campos:
- Subscription: Seleccionar suscripción de Azure en la cual se va a crear Databricks
- Resource group: Nombre del recurso en donde se va a crear el Workspace Databricks
- Workspace name: Nombre asignar al Databricks
- Region: Región donde se quiere desplegar el servicio
- Pricing Tier: Plan de precio, seleccionar Premium (+ Role-based Access controls)
Las configuraciones adicionales son de networking (redes), advanced y tags las cuales se pueden dejar configuradas por defecto en caso de que no se necesite enlazar el Workspace de Databricks a una vpn o asignar politicas de proteccion de datos.
2. Permitir el control de acceso a el Workspace:
Para este paso vamos a nuestro espacio de trabajo de Databricks creado en el paso 1 y damos clic en lanzar Workspace. Realizando esto se abrirá en una nueva pestaña el nuestro espacio de trabajo que lucirá similar a la siguiente imagen.
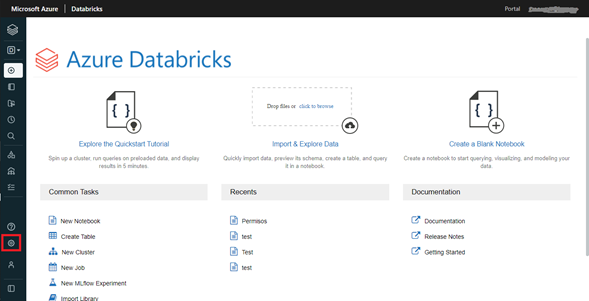
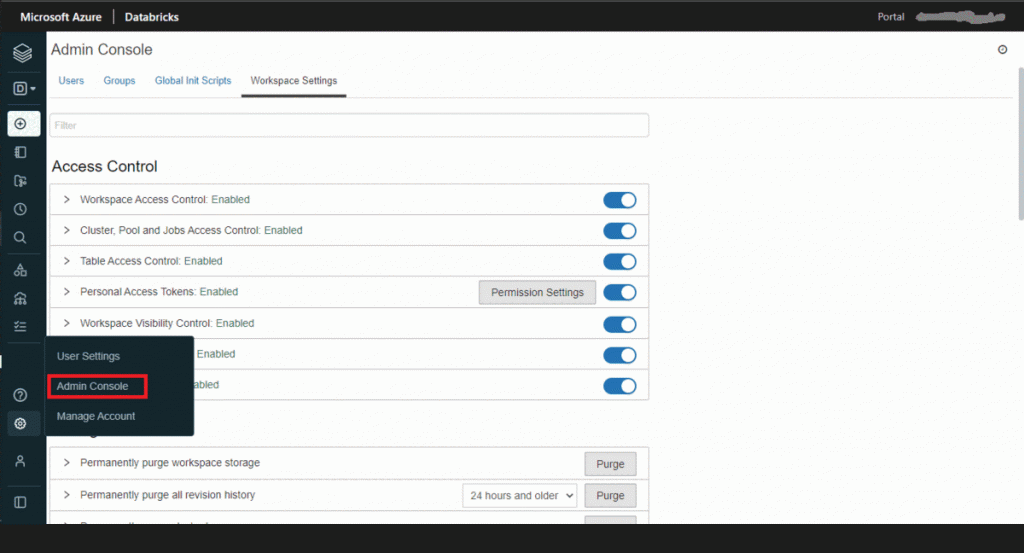
Una vez dentro del Workspace, dar clic en settings (remarcado en el cuadro rojo) y este botón nos desplegara un listado con 3 opciones, seleccionaremos Admin Console y dentro de esta sección navegaremos a la parte de Workspace Settings. Dentro de esta sección habilitamos las dos opciones de:
- Cluster, Pool and Jobs Access Control
- Table Access Control
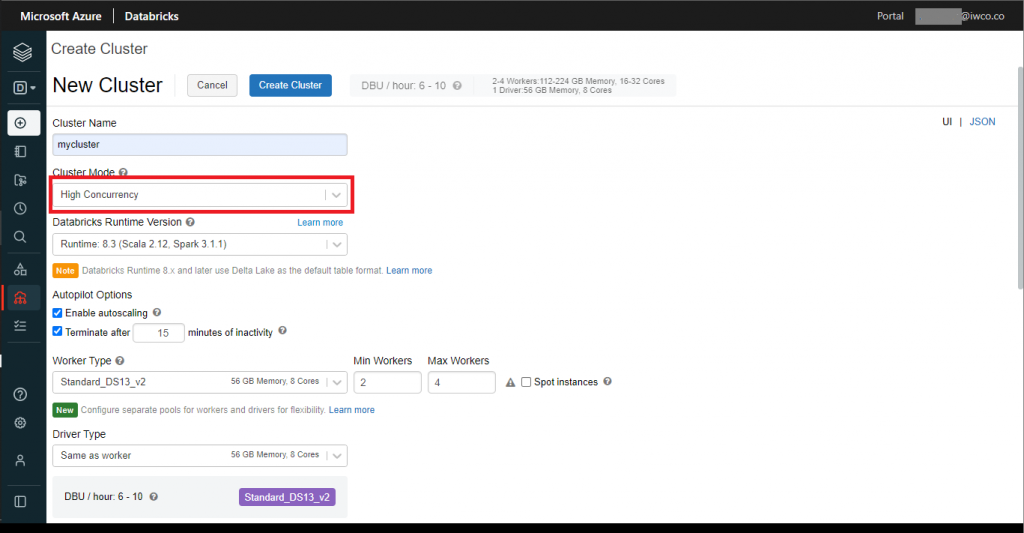
3. Crear clúster de alta concurrencia: en este paso crearemos un clúster de alta concurrencia el cual nos permitirá gestionar el acceso a tablas y ejecutar permitir solo comandos SQL y Python. Tambien puede encontrar sobre cómo hacerlo aquí.
Para crear el clúster damos clic en la sección de compute (parte izquierda de nuestro workspace), seguidamente dar clic en el botón create. Se desplegará una pantalla donde requerirá los siguientes campos:
- Cluster Name: nombre de cluster
- Cluster Mode: seleccionar High Concurrencey
- Databricks Runtime Version: versión de escala y spark que queremos utilizar (se puede dejar la seleccionada por defecto)
- Enabling autoscaling: permitirá hacer uso adecuado de el numero de nodos dependiendo de la carga de trabajo
- Terminate after: tiempo para que se apague el clúster automáticamente, si nadie está trabajando sobre el.
- Worker Type: tipo de nodo para el clúster (seleccionar la capacidad que se necesite)
- Driver Type: tipo de clúster para el driver (se puede dejar el mismo como el worker)
- Enable table access control and only allow Python and SQL commands, dejar casilla seleccionada.
4. Crear notebook, usuarios y grupos dentro de nuestro Databricks worksapce:
Para este tutorial se utilizará una base de datos (esquema) alojada en el clúster de nuestro Databricks Workspace. Pero también se puede realizar sobre cualquier objeto de Databricks como lo son las tablas.
4.1 Crear un notebook en donde vamos a crear y ejecutar los scripts que permitirán la asignación de permisos sobre los roles.
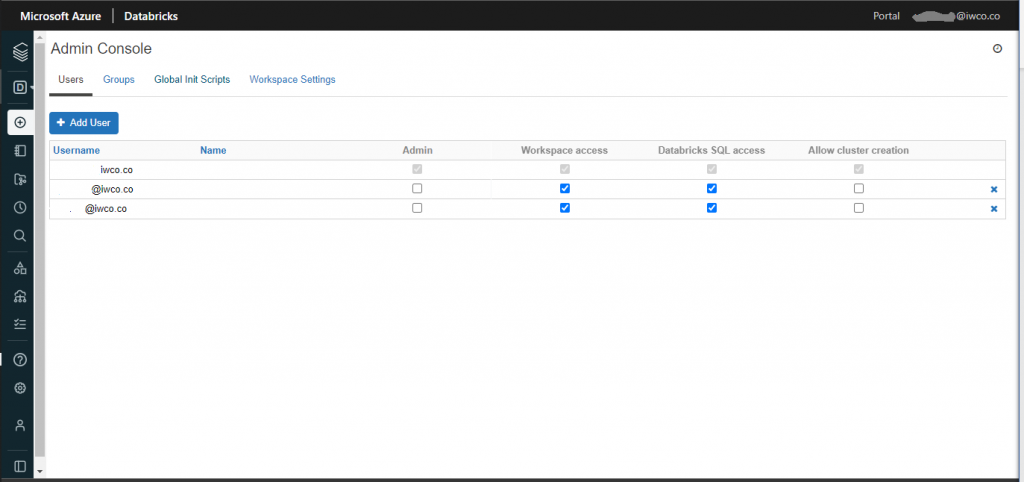
4.2 Agregar usuarios a nuestro Workspace:
Para esto debemos ir a la sección de Admin Console (ver paso 2) y seleccionar la pestaña de Users y dar clic en el botón de Add User. Como buena práctica es importante que los usuarios que no sean administradores no tengan acceso para crear clústeres.
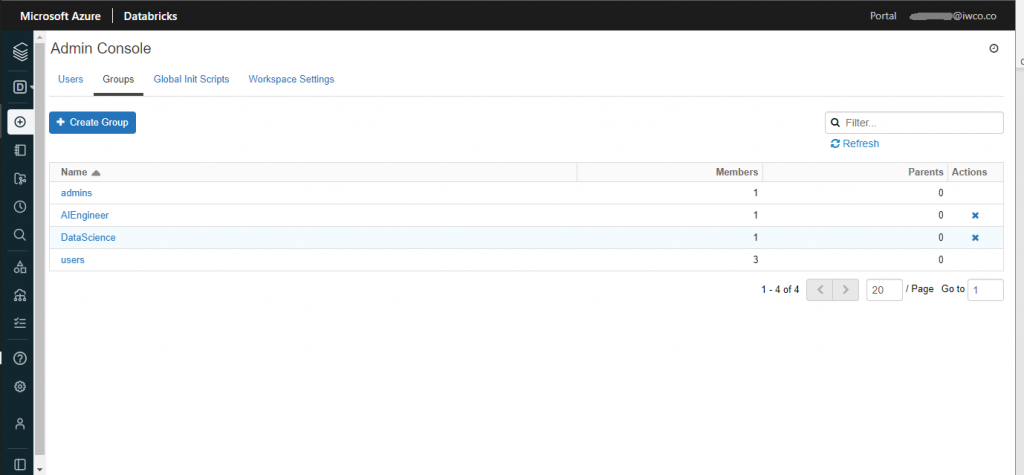
4.3 Crear grupos a partir de estos usuarios.
Los grupos permitirán una mayor gobernanza sobre los roles y privilegios que puedan ser asignados a un objeto. En este tutorial trabajaremos con el grupo de DataScience.
5. Asignar permisos (Python):
En este paso se asignarán permisos a el grupo DataScience sobre la base de datos llamada “default”.
Parte de codigo
Las siguientes celdas de codigo estan escritas en el lenguaje Python; en la primera celda definiremos el nombre de la base de datos y el grupo.
database = 'default'
group = 'DataScience'En la siguiente celda se asignarán los permisos de ‘usage’, ‘select’ y ‘modify’. Es importante que para cualquier permiso que se valla asignar, este se debe agregar con el permiso de ‘usage’.
permissions = 'usage, select, modify' #el permiso usage siempre de ir para poder realizar cualquier operacion sobre el objeto en este caso la base de datos
print(f'Asignando permisos de {permissions} sobre la base de datos {database}')
spark.sql(f"grant {permissions} on database {database} to {group} ")En la siguiente celda se comprobarán los permisos asignados al grupo DataScience sobre la base de datos default.
spark.sql(f"show grant {group} on database {database}").display()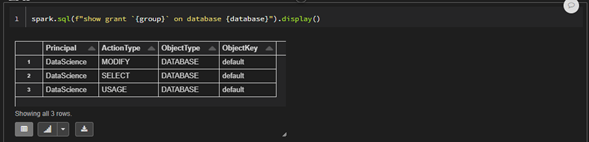
6. Denegando permisos
Ahora vamos a denegar el permiso de modificar sobre la base de datos ‘default’ para el grupo DataScience.
deny_permissions = 'modify'
print(f'Denegando permiso de {deny_permissions} sobre la base de datos {deny_permissions} para el grupo {group}')
spark.sql(f"deny {deny_permissions} on database {database} to {group}")
Verificando que el permiso de modificar fue denegado
spark.sql(f"show grant `{group}` on database {database}").display()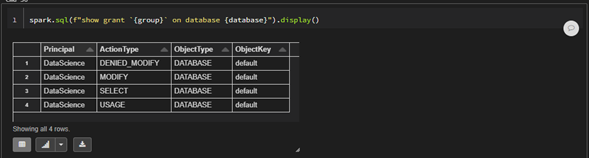
Como se puede observar ahora el grupo DataScience tiene dos tipos de acciones de modificacion sobre la base de datos ‘default’ y el tipo de accion predominante siempre va a ser el denegado en este caso ‘DENIED_MODIFY’.
7. Revocar permisos:
En muchas ocasiones es necesario volver asignar un permiso sobre un grupo al cual previamente fue denegado. Para realizar esta operacion, es necesario primero revocar el permiso (tipo de accion) y volverlo asignar sobre el grupo o usuario. Para este escenario donde denegamos el permiso de modificar para el grupo DataScience, vamos a ver la forma en que se revoca este permiso.
revoke_permissions = 'modify'
print(f'revocando permiso {revoke_permissions} sobre la base de datos {database} para el grupo {group}')
spark.sql(f" revoke {revoke_permissions} on database {database} from {group}")Verificando que el permiso de modificar haya sido revocado
spark.sql(f'show grant `{group}` on database {database}').display()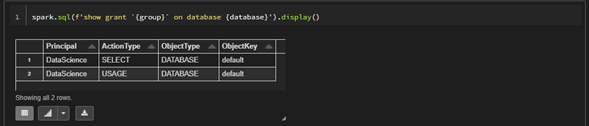
Como podemos apreciar el permiso modify ya no está ni denegado ni creado para el grupo DataScience, para volver asignarlo se podría ejecutar de nuevo el siguiente comando.
permiso_again = 'modify'
print(f'Asignando permisos de {permiso_again} sobre la base de datos {database} para el grupo {group}')
spark.sql(f"grant {permiso_again} on database {database} to {group} ")Para modificar permisos sobre una tabla, simplemente se cambia la palabra database por table en la sentencia SQL y reemplazando el nombre de la base de datos por el nombre de la tabla. Esto aplica para todas las operaciones de asignar, denegar y revocar permisos, aunque en proyectos donde hay una gran cantidad de tablas es mejor darlos a nivel de base de datos. El siguiente es un codigo de ejemplo para asignar permisos de modificar al grupo DataScience sobre la tabla ‘tabla1’.
revoke_permissions = 'modify'
table_name = 'Tabla1'
group = 'DataScience'
spark.sql(f" revoke {revoke_permissions} on TABLE {table_name} from {group}")En este tutorial se realizó el despliegue desde el Workspace de Databricks, pasando por la creación del clúster con sus configuraciones iniciales y por ultimo las sentencias SQL a ejecutar para conceder permisos sobre un objeto de Databricks en este caso una base de datos (Esquema). Se pueden conceder, denegar y revocar muchos más tipos de permisos sobre cada uno de los objetos ya dependiendo del escenario que se tenga se puede consultar la documentación oficial de Databricks.